I’m excited to see the marketing field getting more interested in correlation data and metrics around SEO. There’s a lot of folks citing data from SearchMetrics’ UK Study, from Mark Collier’s Open Algorithm project, and from Moz’s own ranking factors and follow-up reports.
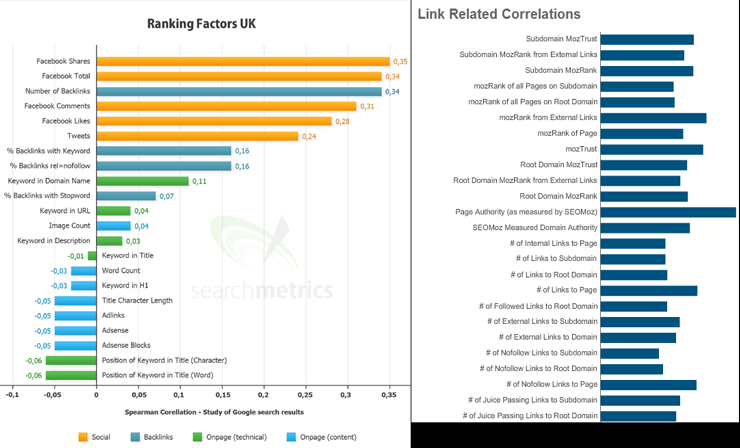 (Searchmetrics’ study at left, OpenAlgorithm at right)
(Searchmetrics’ study at left, OpenAlgorithm at right)
The trouble is how this data gets perceived and interpreted by practitioners and those around them in a marketing organization, and I need to take at least partial blame. When we first started using correlation data at Moz, we mistakenly called it “ranking factors.” That’s not what these datapoints are showing. This type of data shows us the relationship between pages that have particular features and their general performance across a large number of search queries. I think this graphic can explain better than any words:
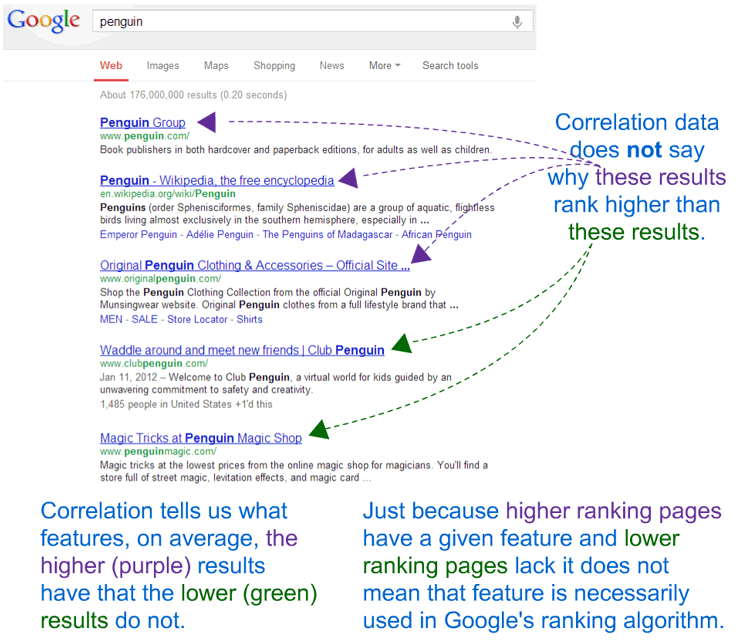
We cool now? Correlation data isn’t (necessarily) showing us ranking factors (it might be, but probably not, as features Google/Bing use are likely way more complex than the simplistic metrics used in these studies). Correlation data shows us features that are more likely to appear on pages that rank higher than on pages that rank lower. Higher correlations mean a higher chance that a page with that feature (or more of that feature) will outperform pages without it (or with less of it).
The following are my opinions on this type of data and how it should be used:
- If Google says “we don’t use that feature in our ranking algorithm” and the correlation data says it’s a feature that performs very highly, that probably means there’s a connection between the feature and something Google does use. For example, a large number of Facebook shares probably means that a page is interesting to a lot of people, which often carry other signals of quality, relevance, popularity, and importance (which Google might be measuring in lots of different ways).
_ - Just because a feature is poorly correlated doesn’t mean it will necessarily hurt you to optimize that feature. On page features, for example, perform pretty terribly in all studies of this type, but that’s likely because a large number of the top ranking results all do the basics on on-page optimization, so it’s hard to stand out.
_ - Features reported on in correlation studies to date have tended to be simplistic. If we built a truly great algorithm for topic modeling, we might find a much better correlation with ranking performance.
_ - Correlation data of this type always refers to non-personalized, non-geo-biased results, and usually only to standard web results (not videos, images, local results, onebox stuff, knowledge graph, instant answers, ads, or anything else that’s often found when performing a search). This doesn’t make the data less useful – it just makes the information provided applicable to only those standard types of results.
_ - Watching the changes in these correlations over time, particularly for a given set of results, could be extremely useful. I think the next big step in search engine correlation analysis is to monitor changes over time, to see the relative increases or decreases that may occur. This has certainly been fascinating to watch in the Mozcast data.
_ - What can I really do with this data? Well, when I see a feature like Facebook shares performing highly, I start to strategize about how we can make content that folks on Facebook will be likely to share, not because I believe that will necessarily have a direct impact, but because I want my content to be more like the stuff Google is ranking at the top, and optimizing toward Facebook shares is likely to be a solid proxy for whatever they do use. Likewise, when I see that AdSense units have a negative correlation, I feel good that Google’s probably not being corrupt and rewarding their own ad service, and I feel no additional pressure to use it. I think those types of takeaways are indicative of how this data can be put to pragmatic use.
For those who create this type of research, and those who use it, I hope this post sheds a bit more light on what it really means, and how we can apply it.